例題14-1:手作業でなんてやってらんない 再び¶
B: あ、Aさんこんにちは。
A: おう。こんにちわ。B君がこんなに朝早く来るのはめずらしいな。
B: いや、ウチのPCがなんか調子悪くて。大学でSkype使おうと思って。
A: なんだ。たまに早く来たと思ったら。急ぎの用事なのか?
B: あー、いや、その。急ぎじゃないです。
A: そうか。そうしたら今ちょっとこないだ被験者してもらった実験( 例題12-5 )のデータ見てるから、終わるまでちょっと待ってくれ。
B: ああ、あのペダル使う奴ですか。結構ペダルが固くてしんどかったなあ。
A: 足で踏む入力装置だからな。ちょうどいい、今からデータの読み込みを始めるところだから、例題4の実践編のつもりで横で見てなさい。
B: 例題4ってなんでしたっけ。…ああ、「手作業なんてうんざりだ」っていういかにもAさんらしい奴ですね。テキストファイルの読み書き。
A: Aさんらしいってのは余計だ。とにかく、20人分のデータがあって、それぞれ6種類の実験条件に参加している。 1条件1テキストファイルに結果が保存されていて、1行目に条件名が記されている。参加者1人あたり6ファイルあることになるが、データファイルは参加者ごとにフォルダにまとめて格納されている。 で、データファイルの2行目以降には1試行1行で…
B: ちょ、ちょっと待ってください。わからなくなってきました。
A: 世話が焼けるなあ。こんな感じだ。
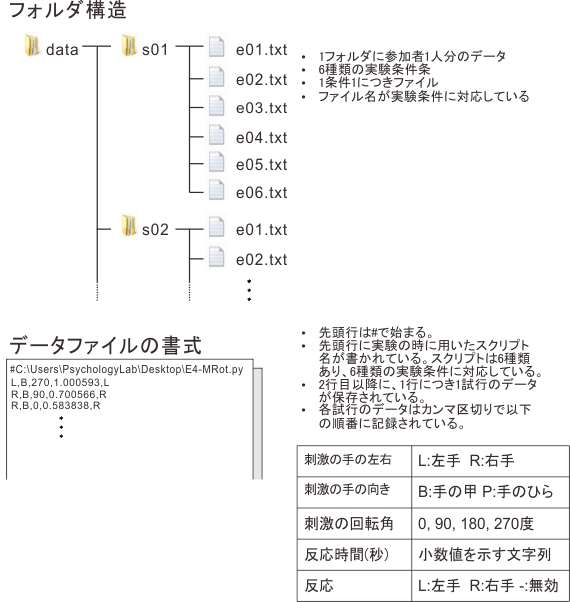
B: ふむふむ、なるほど…。ん? ファイル名で条件がわかるのなら、データファイルの1行目に条件を書いてなくてもわかるんじゃないですか?
A: うむ。この実験は私の実験じゃなくてFさんの実験プログラムを代わりに書いてあげたものなんだよ。で、別にファイル名は条件名に対応していなくてもよかったんだが、彼女がそういう風にファイル名をつけたから。
B: えーっ。Aさんがぼくのために実験プログラムを書いてくれるなんてありえないじゃないですか! ずるい、えこひいきだ!
A: ひいきなんかしてないっつーの。いろんな人と仕事をしているとだな、断れない事情ってもんがあるんだ。Bくんはその点バックに誰もついてないのでややこしくない。 (注:この物語はフィクションです)
B: ぶーぶー。
A: ま、そういうしがらみなしに付き合えるってのは貴重だから、私ぁB君との雑談を楽しんでるよ。ホント。あ、読者の皆様、 この物語は本当にフィクションなんであれこれ詮索しないでください。 ハイ。
B: そんなに取り繕うんなら違うストーリーにしたらいいのに。
A: 何か言ったか? とにかく、データファイルの中にも実験条件を知る手掛かりを残しておけば、万一データファイル名を付け間違えてもどこで間違えたのかを確かめることが出来るから、決して無駄にはならない。これはまじめな話。
B: フィクションがどうとかいう言い訳よりも「無駄じゃないよ」の方が強調されるべきだと思いますが…。
A: ま、元ネタになった実験はこれに加えて統制条件もあったりして結構複雑だったのですが、話がややこしくなるのでその辺はアレンジしているでござるよ。読者の皆さま。
B: Aさーん、いいかげん本題に戻ってくださーい。
A: お、すまんすまん。これをファイル1つずつ開いてExcelに貼り付けて…とかやるのはうんざりなので、pythonで一気に読み込んでみよう。こういう時に威力を発揮するのがos.walk()だ。
B: walk? 歩く?
A: 実例を見てもらった方が早いな。
行番号なしのソースファイル(14-1a.py)およびデータファイル→ 14-1.zip
1import os
2
3nFiles = 0
4
5for root, dirs, files in os.walk(os.getcwdu()):
6 print 'Directory: %s' % root
7 for f in files:
8 r,e = os.path.splitext(f)
9 if e.lower() == '.txt':
10 print ' %s' % f
11 nFiles += 1
12print '%d files found.' % nFiles
A: この例ではos.getcwdu()とos.path.splitext()も重要な役割を果たしているけど、これらの関数は 例題4-2 で紹介しているから忘れた人は確認しておいてほしい。
B: えー。手抜きだなあ。確かos.getcwdu()はカレントディレクトリを得る関数でしたよね。os.path.splitext()は…なんだっけ。
A: ファイル名をベースネームと拡張子に分解する関数だ。例えばr, e = os.path.splitext( 'hoge.txt' )ならrに'hoge'、eに'.txt'が入る。
B: ああ、そうでしたそうでした。
A: それを踏まえて5行目のos.walk()だが、これはforと組み合わせて使うのが一般的だ。この例では、os.walk()の引数に与えたディレクトリからスタートして、そのディレクトリとサブディレクトリに存在するディレクトリ名やファイル名を次々とroot, dirs, filesに代入してくれる。 root, dirs, filesをうまく使えば、あるディレクトリの下に含まれる複数のディレクトリやファイルに対して繰り返し処理を行うことが出来る。
B: ??? よくわかりません。
A: やってみるとわかりやすいな。 14-1.zip をダウンロードして展開してもらって、IPythonを起動してそのディレクトリへ移動して。
B: えーと、保存。D:\workに展開してみます。…dataってディレクトリが出来てますけど、ここをIPythonのカレントディレクトリにしたらいいんですね?
A: そう。
B: ええと、ipthonを起動して、cd D:\work\data 、と。出来ました。
A: じゃあ次のように入力してみて。
In [2]: for root,dirs,files in os.walk(os.getcwdu()):
B: ん? なんだか緑色の...が表示されましたが。
In [2]: for root,dirs,files in os.walk(os.getcwdu()):
....:
A: それは今入力したfor文が完結してないから続きを入れてくれって状態だ。続けて以下のように入力してみて。緑色の部分はIPythonの出力だから入力しなくていいぞ。
In [2]: for root,dirs,files in os.walk(os.getcwdu()):
....: print '--- %s ---' % root
....: print files
....:
B: 入力しました。printの前の空白はIPythonが勝手に入れてくれるんですね。便利。
A: 最後にこのfor文を閉じよう。pythonでは行頭の空白でfor文の範囲を決めるんだから、for文を終わらせる場合はIPtyhonが挿入してくれている空白を削除してEnterすればいい。
B: えーと、Backspace、Enterっ、と。
In [2]: for root,dirs,files in os.walk(os.getcwdu()):
....: print '--- %s ---' % root
....: print files
....:
--- d:\work\data ---
[u'14-1a.py', u'14-1b.py']
--- d:\work\data\s01 ---
[u'e01.txt', u'e02.txt', u'e03.txt', u'e04.txt', u'e05.txt', u'e06.txt']
--- d:\work\data\s02 ---
[u'e01.txt', u'e02.txt', u'e03.txt', u'e04.txt', u'e05.txt', u'e06.txt']
--- d:\work\data\s03 ---
[u'e01.txt', u'e02.txt', u'e03.txt', u'e04.txt', u'e05.txt', u'e06.txt']
--- d:\work\data\s04 ---
[u'e01.txt', u'e02.txt', u'e03.txt', u'e04.txt', u'e05.txt', u'e06.txt']
(以下省略)
A: わかるかな? まず最初にカレントディレクトリのd:\work\dataからスタートして、rootにディレクトリ名、filesにそのディレクトリに含まれるファイル名のリストが代入されている。 そして、次はd:work\data\s01に移動して、今度はrootにd:work\data\s01、filesにはd:work\data\s01に含まれるファイル名のリストが代入されている。あとはひたすらこの繰り返しだ。 この例ではディレクトリの構造が単純だしs01からs20までに含まれるファイル名が全部同じだからあまり面白くないが、もっと複雑な構造を持つディレクトリでやってみると面白いからぜひ試してみてほしい。 あ、複雑って言ってもC:\Windowsとか/usrとかでやったら複雑すぎて死ねるので注意。
B: へえ、これは便利。dirsには何が入るんですか?
A: rootに含まれるディレクトリだな。今の例でprint filesをprint dirsにしてみたらすぐわかる。
In [3]: for root,dirs,files in os.walk(os.getcwdu()):
....: print '--- %s ---' % root
....: print dirs
....:
--- d:\work\data ---
[u's01', u's02', u's03', u's04', u's05', u's06', u's07', u's08', u's09', u's10',
u's11', u's12', u's13', u's14', u's15', u's16', u's17', u's18', u's19', u's20']
--- d:\work\data\s01 ---
[]
--- d:\work\data\s02 ---
[]
--- d:\work\data\s03 ---
[]
--- d:\work\data\s04 ---
[]
(以下省略)
B: ん? s01からs20まで、ずっと[]ばかりだ。
A: s01からs20まではその下にディレクトリがないんだから、空のリストになるのは自然だろ。
B: ああ、そうか。なるほど。
A: これを踏まえてさっきの14-1a.pyに戻るぞ。7行目でfilesを使ってfor文を組んでいる。こうすると、ディレクトリを順番に巡りながら、それぞれのディレクトリに含まれるファイルひとつひとつに対して同じ処理を繰り返すことが出来る。便利だろ。 ここではとりあえず、ディレクトリを移動するたびにrootを表示して(6行目)、そこに含まれるファイルのうち拡張子が'.txt'のものだけ表示しながら数をカウントしている。 そして最後にカウントした拡張子が'.txt'のファイル数を表示して終了している。実行してみよう。
In [5]: run 14-1a
Directory: d:\work\data
Directory: d:\work\data\s01
e01.txt
e02.txt
e03.txt
e04.txt
e05.txt
e06.txt
Directory: d:\work\data\s02
e01.txt
# 中略
e06.txt
Directory: d:\work\data\s20
e01.txt
e02.txt
e03.txt
e04.txt
e05.txt
e06.txt
120 files found.
B: 参加者20人、1人につき6ファイルで合計120ファイル。合ってますね。
A: うむ。こうすると欠けているファイルがないかすぐわかる。さて、ここで終わるのもアレなんで例題14-2に移る前にグラフくらい描いておくか。
B: あのー、ちょっと待ってください。
A: ん? 何?
B: os.walk()でディレクトリを移動しながらディレクトリやファイルを追加したり削除したりしたらどうなるんですかね?
A: む。相変わらず妙に鋭い質問を思いつく奴だな。心理実験のデータ処理でそういう事をする必要があるとは思わないんでパスしてもいいんだが、os.walk()にtopdownという引数があることだけ言っておこう。 通常、os.walk()は上の例でみたようにディレクトリ階層の上から下へ向かって処理を進めていくが、topdown=Falseを指定すると、下から上へ向かって処理を進める。ディレクトリを削除してしまうような場合は、下から上へ向かって処理しないとおかしなことになってしまう。 ま、詳しくは自分で試してみてくれ。ていうか、そんな鋭い質問を思いつくような奴は自分で試せ。
B: うわ。逆ギレだ。
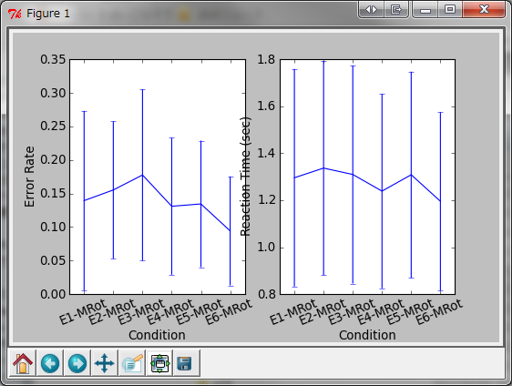
A: これは「逆」なのか? まあどうでもいい。まずは6種類の条件ごとのエラー率と反応時間の平均をプロットしてみよう。 反応時間の平均の計算の際にはエラーを犯した試行も含むものとする。
行番号なしのソースファイル(14-1b.py)およびデータファイルは先ほどの 14-1.zip に含まれています。
1import os
2import os.path
3import pylab
4
5cndList = ['E1-MRot','E2-MRot','E3-MRot','E4-MRot','E5-MRot','E6-MRot']
6
7L = 0
8R = 1
9NA = 2
10B = 0
11P = 1
12
13errorRate = []
14reactionTime = []
15
16for (root, dirs, files) in os.walk(os.getcwdu()):
17 tmpErrorRate = [0 for i in range(len(cndList))]
18 tmpReactionTime = [0 for i in range(len(cndList))]
19 for f in files:
20 r,e = os.path.splitext(f)
21 if e.lower() == '.txt':
22 fp = open(os.path.join(root,f),'r')
23 line = fp.readline()
24 for i in range(len(cndList)):
25 if line.find(cndList[i])>=0:
26 cndidx = i
27 break
28
29 tmpData = pylab.zeros((96,5))
30 idx = 0
31 for line in fp:
32 data = line.rstrip().split(',')
33 if data[0]=='L':
34 tmpData[idx,0] = L
35 else:
36 tmpData[idx,0] = R
37 if data[1]=='B':
38 tmpData[idx,1] = B
39 else:
40 tmpData[idx,1] = P
41 tmpData[idx,2] = int(data[2])
42 tmpData[idx,3] = float(data[3])
43 if data[4]=='L':
44 tmpData[idx,4] = L
45 elif data[4]=='R':
46 tmpData[idx,4] = R
47 else:
48 tmpData[idx,4] = NA
49
50 idx += 1
51
52 fp.close()
53
54 tmpErrorRate[cndidx] = sum(tmpData[:,0]!=tmpData[:,4])/96.0
55 tmpReactionTime[cndidx] = pylab.mean(tmpData[:,3])
56
57 errorRate.append(tmpErrorRate)
58 reactionTime.append(tmpReactionTime)
59
60errorRate = pylab.array(errorRate)
61reactionTime = pylab.array(reactionTime)
62
63pylab.subplot(1,2,1)
64pylab.errorbar(pylab.arange(6),pylab.mean(errorRate,0),yerr=pylab.std(errorRate,0,ddof=1))
65pylab.xlim([-0.5,5.5])
66pylab.xticks(pylab.arange(6),cndList,rotation=22.5)
67pylab.xlabel('Condition')
68pylab.ylabel('Error Rate')
69
70pylab.subplot(1,2,2)
71pylab.errorbar(pylab.arange(6),pylab.mean(reactionTime,0),yerr=pylab.std(reactionTime,0,ddof=1))
72pylab.xlim([-0.5,5.5])
73pylab.xticks(pylab.arange(6),cndList,rotation=22.5)
74pylab.xlabel('Condition')
75pylab.ylabel('Reaction Time (sec)')
76
77pylab.show()
B: だはっ、14-1a.pyが短かったから油断していましたが、結構長いですね。
A: 16行目のos.walk()に対するforループと19行目のfilesに対するforループから成っているという点では14-1a.pyと全く同じ構造だ。 最初のポイントは23から27行目。ここではファイルを開いてまずreadline()で1行目だけを読み出し、cndListに保存されている実験条件名のどれにマッチするかを確かめている。 25行目のline.find(cndList[i])は、lineに格納されている文字列の中にcndList[i]が含まれていたら0以上の値が戻ってくるので、0以上になればそこでループを打ち切ってcndListの何番目の要素にマッチしたかを変数cndidxに保存する。 以後、データを格納するときにこのcndidxが格納すべき場所を教えてくれるカギになる。
B: ふむふむ。
A: で、29行目からは基本的に 例題4-2 と同じだから、わからない人は例題4-2も復習してほしい。 新しいテクニックとしては、データを一時的に保存するためにpylab.zeros()を使っていることかな。 これは引数で指定したサイズのゼロ行列を作る関数で、1条件96試行あるので96行、1行あたり5種類のデータがあるので5列。
B: リストじゃダメなんですか?
A: 別にリストでもいいんだけど、最後にエラー率とか計算するときにnumpy.ndarrayの強力な演算機能を使いたいのでここは零行列を生成するpylab.zeros()で。 引数の(96,5)というタプルは、96行5列の行列を作ることを意味している 。 もちろんリストでもできるので腕試しにやってみるといい。
B: …謹んで遠慮いたします。
A: あとは各自で読んでほしいんだけど、取り上げておきたい気遣いが二つ。まず、7行目から11行目。 実験刺激の種類や反応は'L'とか'R'とかいう記号で表現されている方がわかりやすいが、numpy.ndarrayに突っ込んであれこれ演算を駆使するときは数値の方が便利な場合もある。 そこで、7行目から11行目のように値を変数に放り込んでおいて、32から48行目のように使う。そうすると行列に実際に保存されている値は0とか1とかだが、後でプログラムを読む時に「0って何を表してるんだっけ?」などと悩まなくて済む。
B: 例題1のどっかでもそんなこと言っていましたね。
A: 次回の例題14-2でさっそくご利益がある予定だ。あともう一つは、17、18、24行目に出てくるlen(cndList)といった式や、57、58行目に出てくるappend()によって被験者のデータを蓄積する方法だ。 今回は6条件、参加者数は20と決まっているんだから、len(cndList)は6と書けばいいし、データもいちいちappend()するのではなく最初から参加者数分のデータを保存できるサイズの行列を確保した方が処理も早い。 でも、このようにしておくと条件数が異なる別の実験のデータ読み込みに簡単に流用出来るし、参加者数を固定せずにappend()するようにしておけば参加者を追加した時にもプログラムを書きなおす必要がない。
B: ふうん。全然気が利かなさそうな顔して、いろんなこと考えているんですねえ。
A: 顔は関係ないわい。何かわからないことはある?
B: えーっと…。そうだなあ。48行目なんですが、NAっていうのは反応がLでもRでもないときの値なんですよね。これって具体的にはどういうときにNAになるんですか?
A: この実験では3秒以内に反応できなかった時にはエラーとして扱われるんだ。で、3秒以内に反応しなかった時はLもRもないのでNAというを入れてある。ちなみに反応時間の欄には3.0000が保存される。
B: ふむふむ。それって反応時間の平均に含んでいいのかなあ。
A: エラーの試行を除いて平均を計算するのは例題14-2で扱うんで、それはその時に。
B: あ、そうですか。あと、54行目も意味不明なんですが…。tmpErrorRateっていう変数名からしてエラー率が格納されているんだと思いますが、右辺の式がよくわかりません。
A: tmpData[:,0]に提示された刺激、tmpData[:,4]に反応が格納されているのはいいな? で、tmpData[:,0]!=tmpData[:,4]とすると、両者が一致していない行はTrue、一致していればFalseが格納された列ベクトルが得られる。 これに対してsumを適用するとTrueは1、Falseは0として扱われるので、計算結果はTrueの個数、すなわち刺激と反応が一致していない試行数になる。これを1条件の試行数96.0で割ればエラー率となる。
B: むむむ…。あとでじっくり考えます。
A: 自分で書いておいて言うのもなんだが、Trueは1として扱われるとかそんな変な性質に頼らないプログラムを書くべきだろうな。 で、tmpErrorRate、tmpReactionTimeに格納された参加者1人分の計算結果を57、58行目でerrorRate、reactionTimeにappend。errorRateとreactionTimeには全参加者のデータがどんどん蓄積されていくことになる。
B: ふむふむ。
A: で、全員分読み終わったら60、61行目でリストとして保存してきた全参加者のデータをpylab.array()でnumpy.ndarray型に変換。 ここから先は 例題12-2 の復習だね。 あの時は 敢えて解説しなかった pylab.errorbar()を使ってエラーバーを描いてある。
B: ああ、Aさんが 手抜きして解説しなかった pylab.errorbar()ですね。
A: うむ。 教育的配慮から解説しなかった pylab.errorbar()だ。で、使い方だが…見りゃわかるでしょ。わからなかったらIPythonでpylabをimportしてhelp pylab.errorbarして。終了。
B: げっ、今度こそ解説するかと思ったのに。ひどい。
A: 最初は解説するつもりだったんだけど、意外と例題14-1が長くなったんで疲れた。そうそう、Matlabから引っ越してきた人はエラーバーの値を指定するときにyerr=hogehogeといった具合にyerrという引数として与えないといけないので注意してね。以上。 あとpylab.subplot()はMatlabな人にはお馴染みでしょうが、1枚のウィンドウに複数のグラフを描くための関数です。これもhelp pylab.subplot()してくだせえ。
B: まったく、どの口で教育的配慮とかいうかな。…ん? これ、pylab.arange(6)の6って条件数の6ですよね。
A: うん、そうだけどそれが?
B: それが、じゃないでしょ! ついさっき「条件数はlen(cndList)ってしておけば条件数が異なる別の実験データの解析にも流用できる(キリッ」とか言ったとこでしょ!
A: ああ、そうだな。でもpylab.arange(len(cndList))とか書いたら長ったらしくてうっとおしいじゃん。ただでさえこの行は長くて枠内に入りきらないのに。
B: 本当にどうしようもない人だな…
A: そんなわけで、この続きは例題14-2で。その頃までにはやる気が復帰しているといいんだがね。