例題14-5:統計パッケージへバトンタッチ¶
A: ちょっといろいろあって作者が落ち込んでいるらしいから、今日は淡々といくぞ。
B: なんだか知りませんけど落ち込んでるなら休んだらいいのに。
A: この例題もあともう一息だからな。講義期間が始まるまでに片付けてしまいたいんだろ(この原稿は3月に執筆)。 今回のサンプルプログラムその1は以下の通り。例によって例題14-3の続きなので、データの14-1.zipと前処理のスクリプト14-3a.pyをダウンロードしてIPythonから14-3a.pyを実行しておいてほしい。 で、その後run -i 14-5a.pyとして実行する。
行番号なしのソースファイル→ 14-5a.py
データファイル→ 14-1.zip
データの前処理を行うスクリプト→ 14-3a.py ※14-1.zipを展開して作成されるdataディレクトリに14-3a.pyを置いてIPython上から実行した後、run -i 14-5a.pyとして実行します。
1fp = open('out.csv','w')
2
3tmp = reactionTime.reshape((20,-1))
4compList = (tmp==tmp).all(axis=1)
5compData = tmp[compList,:]
6
7fmt = ','.join(['%f' for i in range(96)])+'\n'
8for d in compData:
9 fp.write(fmt % tuple(d))
10
11fp.close()
B: 短いですね。ええっと、3行目は例題14-4でやったreshapeか。20行の2次元配列にするのも例題14-4と同じ。
A: うむ。で、4行目と5行目で欠損がない参加者のデータだけを抜き出している。これも例題14-4で詳しく解説したのでわからない人はそちらを見てほしい。 あとはテキストファイルにデータを書きだしているだけだな。以上。
B: ちょ、それだけじゃわかりませんよ。7行目はなんですか?
A: ああ。文字列のjoinメソッドが久々に出てきたからわからないかな。 例題3-4 で簡単に紹介しているんだが、文字列のリストを指定した区切り文字で連結して一つの文字列を作り出す働きがある。
In [11]: t = ['2011','03','21']
In [12]: '/'.join(t)
Out[12]: '2011/03/21'
In [13]: '-*-'.join(t)
Out[13]: '2011-*-03-*-21'
B: んん? '/'とか'-*-'に.join()が付いている??
A: '/'や'-*-'はpythonの文字列型(正確にはstr型)なんだから、当然文字列型のメソッドを呼び出すことが出来る。tという変数に文字列が格納されているときにt.join()と書くことが出来るのと全く同じことだな。
B: これもなんだか落ち着かない書き方だなあ。まあでも意味は分かりました。
A: 区切りに使いたい文字列からjoin()メソッドを呼び出して、引数に結合したいリストを渡すのがポイントだな。私はよく逆に結合したいリストに.join()と付けてしまって書き直すことがある。で、これで7行目の意味はわかるか?
B: ','.join()という形だから、引数のリストを','で連結した文字列を返します。で、リストの中身は…'%f'ばかり?
A: そう。'%f'が96個並んだリストを返す。1行に出力する値が5個だったら'%f,%f,%f,%f,%f\n'と手入力してもそれほど面倒じゃないが、今回は1行に1名の参加者のデータを出力しようとしている。1名分のデータは96個あるから、'%f,'を96個も並べなきゃならん。そんなのコピペでもやりたくない。せっかくpythonを使っているんだから、ここはpythonにさせるべし。','で連結した後は改行文字'\n'を追加して一丁上がりだ。
B: なるほど。これ、96個のデータが全部小数だから'%f'ですけど、整数とか文字列とかあったらこうはいかないんですよね?
A: 整数や文字列が出てくる順番に規則性があるならプログラムで書けばいいが、まあ手で書くのとどちらが楽かはケースバイケースだな。さて、いきなりだがこれで今回の目的はおしまい。出力されたテキストファイルでは、参加者1名のデータが1行に並んでいて、同じ条件のデータが1列に並んでいる。SPSSやstatistica、Rのanovakun()でそのまま読める形式なので、あとはそれぞれのソフトウェアで煮るなり焼くなりすればいい。
B: へ? もう終わりですか? たったこれだけなら、例題14-4で一気にやっちゃったらよかったと思うんですが…。
A: うむ。もうこれで今回の目的は達成しているんだがな、ここからが気配りよ。これ、どの列がどの条件かわかるか?
B: へ? そういえば全然わかりませんね。
A: 前回説明を飛ばした「reshapeで配列の形を変更するとどのようにデータが並び替えられるのか」って点がここで問題になる。reshapeに与えるorderという引数に'C'を指定するか'F'を指定するかによって変わるんだが、その辺りの詳細はhelp reshapeしてみて欲しい。気合充分だったら説明するつもりだったんだけど、今回はパス。代わりにというわけではないが、numpyに教えてもらう方法を紹介する。
B: numpyに教えてもらう?
A: どの列がどの条件に対応しているかを示す「列見出し」をnumpyに作ってもらうのさ。次のサンプルプログラムを見てほしい。
行番号なしのソースファイル→ 14-5b.py
データファイル→ 14-1.zip
データの前処理を行うスクリプト→ 14-3a.py ※14-1.zipを展開して作成されるdataディレクトリに14-3a.pyを置いてIPython上から実行した後、run -i 14-5b.pyとして実行します。
1fp = open('out.csv','w')
2
3LRlist = ['L','R']
4BPlist = ['B','P']
5DIRlist = ['0','90','180','270']
6CNDlist = ['C1','C2','C3','C4','C5','C6']
7nLR = 2
8nBP = 2
9nDIR = 4
10nCND = 6
11
12labels = pylab.empty((20,2,2,4,6),dtype='S10')
13for sbj in range(20):
14 for i in range(nLR):
15 for j in range(nBP):
16 for k in range(nDIR):
17 for l in range(nCND):
18 labels[sbj,i,j,k,l] = str(sbj).zfill(2)+LRlist[i]+BPlist[j]+DIRlist[k]+CNDlist[l]
19
20colLabels = labels.reshape((20,-1))
21fp.write(','.join(colLabels[0,:])+'\n')
22
23tmp = reactionTime.reshape((20,-1))
24compList = (tmp==tmp).all(axis=1)
25compData = tmp[compList,:]
26
27fmt = ','.join(['%f' for i in range(96)])+'\n'
28for d in compData:
29 fp.write(fmt % tuple(d))
30
31fp.close()
A: いきなりプログラムの長さが3倍近くなったが、全然大したことはしていない。3行目から10行目で、条件を示す文字列などを定義している。んで、12行目から18行目で列見出しの文字列を組み立てている。ポイントは、この12行目から18行目が元のデータを作成した14-3a.pyでの順番と同じになっていることだ。ええと、この部分かな?
64 for i in range(nLR):
65 for j in range(nPB):
66 for k in range(nDIR):
67 tmpReactionTime[i,j,k,cndidx] = \
68 pylab.mean(tmpData[correct & (tmpData[:,0]==LRList[i]) & \
69 (tmpData[:,1]==PBList[j]) & (tmpData[:,2]==DIRList[k]),3])
B: あれ? これと14-5b.pyの12行目から18行目は同じ順番なんですか? nLR、nPB、nDIRと並ぶのは同じようですが…
A: んー。for文の順番は本質ではないんだがな。この部分の「鍵」は、幾重にも重なったfor文の一番内側で実行されている文にある。14-3a.pyではtmpReactionTime[i,j,k,cndidx]へ計算結果を格納するように書かれているが、i、j、kはそのすぐ上の数行を見るとわかるようにそれぞれ「右手か左手か(nLR)」、「手のひらか手の甲か(nPB)」、「回転角(nDIR)」に対応している。そして、cndidxは6種類の実験条件に対応していたんだから、ラベルもこれと同じ順番に並べる必要がある。14-5b.pyの18行目はきちんとこの順番に文字列を連結していることを確認してほしい。
B: ええと…。14-5b.pyの18行目は最初いきなり参加者(sbj)になっているみたいですが?
A: おっと。失礼。14-3a.pyでは上に引用した部分で参加者別にデータを集計した後、改めてpylab.arrayで配列を作り直しているからな。最初の次元は参加者に対応していなきゃならない。それ以後の順番はきちんと「右手か左手か(nLR)」、「手のひらか手の甲か(nPB)」、「回転角(nDIR)」、「6種類の実験条件(nCND)」に対応していることを確認してほしい。
B: 確かにそうなってますね。
A: ここでひとつだけ注意しておきたいのが12行目だ。13行目以降の多重for文で生成したラベルを格納するためのnumpy.ndarray型配列を準備しているんだが、今まで解説していないテクニックがふたつ使われている。 まず、pylab.empty()というのは初期化されていないnumpy.ndarray型配列を生成する関数だ。
B: 初期化されていない?
A: そう。例えば今まで出てきたpylab.zeros()なら、配列を確保した後、すべての値を0にセットしてくれる。これが初期化ということだね。似たような関数にpylab.ones()があるが、こいつはすべての値を1に初期化してくれる。その後の使用目的に応じて便利なものを使えばいい。
B: ふむふむ。
A: で、pylab.empty()というのは、配列を確保した後、何も初期化しない。
B: ? 言葉の意味はわかりますが、それにどういう意味があるのかわかりません。
A: ははは、変な日本語だな。でも言いたいことはわかるぞ。そうだなあ、どう説明したらいいかな。例えば、講義室の黒板に書かれた板書は、講義が終わった後に誰かが消さないと、次の講義をする教員が教室に入ってきた時に残ったままになっているよな。ひとつの講義室が次々といろんな講義に使われるように、コンピュータのメモリも次々といろいろなプログラムによって使われる。Pythonで変数を確保すると、前に何かのプログラムが使って今は空いているメモリ上の領域が割り当てられる。前の講義の板書をいちいち消すのに手間がかかるのと同じように、変数のために確保したメモリ上の領域から前のプログラムの痕跡を消すのも手間がかかる。もし、今からpythonで実行しようとしている処理において前のプログラムの痕跡が残っていても支障をきたさないのであれば、いちいちきれいにしなくていいからすぐに渡してよ、と頼んだら速く準備が出来る。この「消さなくていいからすぐに渡してよ」のお願いをするのがpylab.empty()なわけだ。
B: うーん、わかるような、わからんような。
A: C言語のようにメモリを意識しながらプログラムを書かないといけないような言語をやったことがあればすぐにわかるんだがな。「高級」なプログラム言語はメモリの操作を出来るだけ意識させないように作られているから、却ってわかりにくい。
B: ふーん。Aさんの話を聞いてるとC言語はやっとかないといけないのかなあって思いますねえ。
A: 私はC言語から入ったから、他の言語から入った人がどういう風にコンピュータの仕組みを理解するのかというモデルが私の中にないだけなんだがね。特殊なハードウェアを制御しないといけない実験をする分野の人はCとC++は知っておいて損しないと思うけど。とにかく、12行目であともうひとつ解説しておきたいこと。pylab.empty()の引数dtype。これは生成した配列に格納したいデータの型を指定する引数だ。指定できる型の種類はすごくたくさんあるので、代表的なものだけ挙げておこう。
'b' |
論理値(True,False) |
'iN' (N=1,2,4,8) |
Nバイト符号あり整数 |
'uN' (N=1,2,4,8) |
Nバイト符号なし整数 |
'fN' (N=4,8) |
Nバイト浮動小数点小数 |
'SN' (N=1,2,3,...) |
N文字の文字列(非Unicode) |
B: Nバイト? 符号あり?
A: Nバイトというのは、値を格納するのに使う領域の広さを示している。広い方が大きい値まで格納できる。1byteは8bit。8bitで表現できる値は2の8乗=256個。つまり、1byte整数なら256種類の整数を表現できる。符号なし整数なら0から255、符号ありなら-128から127の256種類。
B: はあ。符号あり、なしってそういうことですか。なんで符号ありは-128から128じゃないんだろう?
A: 0を含まないと不便だろ。0を入れたら128か-128のどっちかは除外せにゃ256個に収まらん。
B: あ、なるほど。
A: 同じようにu2なら0から65535。i2なら-32768から32767。u4なら0から4294967295。i4なら-2147483648から2147483647。
B: …なんでそんなにすらすら出てくるんですか。変態?
A: 変態とはなんだ。1byte、2byte、4byteで扱える整数の範囲は知っておくと便利だからな。いろいろプログラムを書いていると自然に覚えるものだ。もっとも今i4の範囲がぱっと思い出せなくてちょっと焦ったが。
B: 範囲を超えた値を代入しようとしたらどうなるんですか? エラー?
A: それがエラーにならないんだよな。入らない桁をばっさり落とした値が入る。
In [14]: a = pylab.array([0,0],dtype='i2')
In [15]: a[0] = 32768
In [16]: a[0]
Out[16]: -32768
B: ??? 超えた分は桁を落とすんですよね? なぜにマイナス?
A: 詳しくは 2の補数表現 とかで検索してくれたまえ。とにかく、dtypeを指定するときはこういう問題があることを注意してほしい。
B: なんでこんなややこしいオプションがあるんですか?
A: そりゃ、1byte整数で済む場合は1byte整数で配列を組んだ方がメモリの利用効率や速度の面で有利だからだよ。まあ、そういうレベルでの最適化が求められるプログラムは心理実験では出てこないと思う。今回のように文字列を代入したい場合以外はdtypeを指定する必要はないんじゃないかな。
B: はあ。そうですか…。ちなみに今まで使っていた配列はどの型だったんですか?
A: ん? dtypeを指定せずにpylab.zeros()を呼ぶと'float64'という型になるようだな。上の表の表記で言えば'f8'だ。
B: そうですか。って、とりあえず聞いてみたけどやっぱりよくわかりません。
A: 普通に整数や小数を使う分には一番精度が良い型だな。「普通に」ってのは複素数を扱えないって意味だが、複素数なんて心理実験でまず使わんだろ。
B: 複素数…。懐かしき高校時代の響き…。
A: だいぶ脱線してきたな。とにかく、今回は文字列を格納したいので'SN'を使う。普通のpythonの文字列型と違って、格納出来る最大文字数を指定しなくちゃいけない。ここでは'S10'として10文字分のスペースを確保している。
B: なんで最大文字数を指定しなきゃいけないんですか?
A: 例題14-3を思い出したまえ。配列は「箱」の大きさを決めにゃならん。
B: あ、そういえばそんな話を聞いたような気が。
A: ずいぶん長くなってしまったが、これで14-5b.pyの解説は終わったも同然。14-5b.pyの12から18行目の処理で、実際のデータと同じ形の配列に条件を示す見出し文字列が格納される。あとはデータをreshapeするのと同じ方法でreshapeすれば、numpyが適切に並んだ列見出しを作成してくれる。20行目だね。続く21行目で、出力ファイルの最初の行に列見出しを出力している。列見出しは1行出力すれば充分だから、最初の1行だけを出力しているわけだね。出力されたCSVファイルをExcelで開くとこんな感じ。
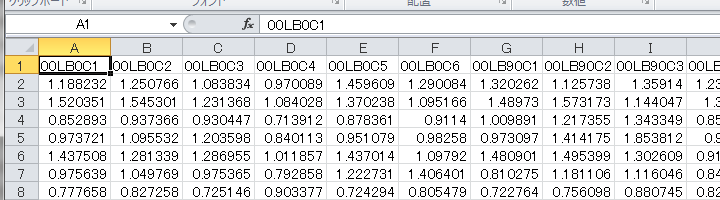
B: 確かに1行目に文字列が出ていますね。ええと、00は参加者番号、Lは左手、Bは手の甲、0は回転角、C1は実験条件1。…これ、参加者番号要らないんじゃないですか?
A: うん。今回はreshapeの動きを追うという目的で参加者番号もつけておいたが、統計パッケージでの処理のためには要らないね。参加者番号を出力しないようにするのは練習問題にしておくかな。
B: ああぅ、藪蛇藪蛇。
A: あー、えー。ちょっとここでSPSSやらStatisticaやらのデータの並べ方を知らない方のために補足しておきますと、これらの統計パッケージで被験者内要因の多要因分散分析を行う場合、1つの行に1名の参加者のデータを並べます。列についてはちょっと文章で説明するのがややこしいんですが、こういう具合に並べます。

B: こういうのは最初に解説しておくべきじゃないんですか?
A: 今、ここまで書いてからSPSS流の並べ方を知らない方が読んでいる可能性に気付いた。許せ。
B: 許せってぼくに言われてもなあ。
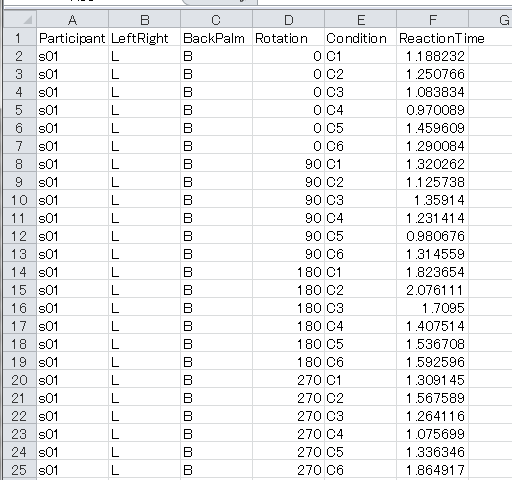
A: とにかく、reshapeで並び替えた出力がちゃんとこの図のように並んでいることを一度は確認しておいてほしい。そうじゃないと後の分析が成立しないからね。さて、長かった例題14-5もいよいよ大団円…と言いたいところだけど、最後にもうひとつ別の形式でデータを出力する例を示しておこう。MatlabのStatistics Toolboxのanovan()やRのaov()などでは、SPSSの形式とは違って下図のように1行1データでずらーっと縦に並べなきゃいけない。この形式でデータを出力するサンプルが以下の14-5c.pyだ。 ここまで読んできた皆さんなら、きっと解説なしで何をしているかわかるはず。ぜひ自力で理解してほしい。強いて注意点を挙げるなら20行目のcontinueかな。それでは、検討を祈る!
B: Aさん、健闘、健闘。
A: これで例題14はおしまい。さようなら~。
行番号なしのソースファイル→ 14-5c.py
データファイル→ 14-1.zip
データの前処理を行うスクリプト→ 14-3a.py ※14-1.zipを展開して作成されるdataディレクトリに14-3a.pyを置いて IPython上から実行した後、run -i 14-5c.pyとして実行します。
1fp = open('out.csv','w')
2
3LRlist = ['L','R']
4BPlist = ['B','P']
5DIRlist = ['0','90','180','270']
6CNDlist = ['C1','C2','C3','C4','C5','C6']
7nLR = 2
8nBP = 2
9nDIR = 4
10nCND = 6
11
12tmp = reactionTime.reshape((20,-1))
13compList = (tmp==tmp).all(axis=1)
14
15fmt = '%s,%s,%s,%s,%s,%f\n'
16
17fp.write('Participant,LeftRight,BackPalm,Rotation,Condition,ReactionTime\n')
18for sbj in range(reactionTime.shape[0]):
19 if not compList[sbj]:
20 continue
21 for i in range(nLR):
22 for j in range(nBP):
23 for k in range(nDIR):
24 for l in range(nCND):
25 fp.write(fmt % ('s'+str(sbj+1).zfill(2),LRlist[i],BPlist[j],DIRlist[k],CNDlist[l],reactionTime[sbj,i,j,k,l]))
26
27fp.close()