14. [Coder編] データの整頓¶
14.1. この章の概要¶
ここまでPsychoPy Builderを使って実験を作成するための解説を行ってきましたが、記録したデータの分析については一切触れてきませんでした。 Builderの実験記録ファイルのフォーマットは、ループが一つしかないシンプルな実験ならいいのですが、いくつもループを含む実験の場合は非常に扱いにくいです。 図14.1 は3つのループを持つ実験が出力する実験記録ファイルを開いた例を示しています。 trial1、trial2、trial3の各ルーチンに置かれたコンポーネントの主要な出力が実験記録ファイル内のどこに出力されているかわかりやすいように色を付けてあります。 PsychoPyのバージョンや実行環境(PythonかJavaScriptか)、設定によっても異なるのですが、多くの場合この例のように空白セルが非常に多くなります。 ルーチンの個数やルーチンに配置されているコンポーネントの個数が多くなると列が非常に多くなり、目的のデータがある場所までスクロールするのも一苦労でしょう。 slider.started, slider.stopped, slider.response, slider.rt,...といった具合に冒頭部が同じ列名が複数含まれるので、表示方法によっては そこで、本章では実験記録ファイルから分析に必要な情報だけ取り出して整頓するPythonコードを考えてみたいと思います。

図14.1 3つのループを持つ実験の実験記録ファイル(PsychoPy Builder 2025.1.1を使用)をExcelで開いた様子。上段はPythonで実行したもの。下段はJavaScriptで実行したもの。trial1、trial2、trial3はそれぞれ最初のループ、2つめのループ、3つめのループ内にある。¶
14.2. CSVファイルやXLSXファイルを読み込む¶
最初の一歩は、Builderの実験が出力するCSVファイルをPythonのスクリプト内で読み込む方法についてです。
筆者はPythonや便利なパッケージがなかったころにプログラミングを覚えた人間なので、 第13章 の open() 関数を用いて1行ずつ読みこんで自分で処理していくのが一番なじむのですが、これから始める人は定番のパッケージの使い方から覚えた方がいいでしょう。
CSVファイルやXLSXファイルを読み込んで処理するのであれば、pandasというパッケージを使うのが便利です。
pandasはPsychoPyに標準で組み込まれているので(正確に言うと依存パッケージなので)、特に下準備をすることなく以下のようにimportできます。
import pandas as pd
第13章 では出てこなかった as というキーワードが使われていますが、これは import A as B で「AというパッケージをBという名前で読み込む」という意味です。
非常に長い名前のパッケージや、パッケージの深い階層にあるモジュールなどを読み込みたい時に便利です。深い階層にあるモジュールの読み込みであれば from でもいいですが、異なるパッケージから同じ名前のモジュールを読み込む必要が出てきたときや、モジュール名と同じ変数をすでに自分のスクリプト内で使ってしまっているときなどに、 as であれば自分に都合がいいように別名を割り当てられるのが大きな利点です。
pandasというモジュール名は決して長くないですが、pandasを本格的に使ってデータ処理を行うときには何度も pandas とタイプすることになりますし、 pandas のモジュールの中にある関数を使う場合にかなり長い名前になってしまうことがあるので import pandas as pd とするのが一般的です。
これまでたびたび名前が出てきたnumpyというパッケージも同様に import numpy as np とするのが一般的です。
さて、pandasを使ってCSVファイルを読み込むには、ずばり read_csv() という関数を使います。
基本形は以下のように引数にCSVファイルのパスを文字列として渡すだけです。
df = pd.read_csv('builder_datafile.csv')
read_csv() の戻り値は pandasのDataframeというオブジェクトで、CSVファイルの内容がまるごと格納されています。ちなみに戻り値を代入している変数が df なのはDataFrameにちなんでいます。
read_csv() は非常に引数が多い関数で、すべて紹介するのは難しいので主なものを 表14.1 に示しておきます。
Builderが出力する実験記録ファイルを読む場合はほとんど指定する必要はないと思います。
引数 |
説明 |
|---|---|
|
カンマ以外の文字でデータが区切られているファイルを読み込みたい場合に、区切り文字を指定する。例えばタブ文字で区切られているなら |
|
sepと同じ。 |
|
データの各列のヘッダーが入力されている行を指定する(ファイルの最初の行が0)。指定した行より前の内容は無視される。ヘッダーの前に何らかの情報が入力されているファイルを読み込む場合に有効。 ヘッダーがないデータを読み込むときは |
|
データのいずれかの列がインデックスである場合、その列の番号を指定する。該当する列が含まれない場合は |
|
|
|
|
|
欠損値としてみなす文字列を列挙したリストを渡す。列ごとに欠損値とみなす文字列が異なる場合は、列名をキーとするdictオブジェクトとして渡す。 |
|
コメントの始まりを示す文字を指定する。例えば |
|
ファイルに使われている文字コードを指定する。 |
- チェックリスト
asを用いてモジュールを独自の名前でimport出来る。pandasを用いてCSVファイルを読み込むことが出来る。
pandasで文字コードを指定してCSVファイルを読み込むことが出来る。
pandasで欠損値とみなす文字列を指定してCSVファイルを読み込むことが出来る。
14.3. pandasのDataFrameから値を取り出す¶
変数 df にDataframeオブジェクトが格納されているときに、データの列数や行数を確認し、データを抽出する方法をいくつか示しておきます。
len(df)とすればヘッダを除いて何行読み込まれたかdf.columns各行のヘッダ文字列df['列名']指定したヘッダを持つ列のデータを抜き出すdf.loc[row, column]行と列を指定してデータを抜き出すdf.iloc[row, column]行と列を数値で指定してデータを抜き出す
loc[] と iloc[] は ( ) ではなく [ ] である点に注意して下さい。
以下のようにシーケンス(リストなど)やスライスを使って複数の列や行を指定することができます。
数値で指定する場合はインデックス(つまり1行目、1列目が0)を使用するのでこの点にも注意してください。
df.iloc[[0,2,4], 7] # 8列目の1, 3, 5行目の値を抜き出す
df.iloc[5, 0:10] # 1から10列目の6行目の値を抜き出す
df.loc[0, 'key_resp.rt'] # key_resp.rt列の1行目の値を抜き出す
df.loc[:, ['key_resp.keys', 'key_resp.rt']] # key_resp.keysとkey_resp.rt列の全ての行を抜き出す
抜き出した部分が複数行、複数列であればDataFrameオブジェクト、一行または一列であればSeriesというクラスのオブジェクトが得られます。 ただひとつの値である場合は、その値の種類に応じて数値だったり文字列オブジェクトとなります。
便利なことに、 loc[] や iloc[] で位置指定に [True, True, False, True, False] のように True と False を行数や列数と同じだけ並べたシーケンスを用いると、 True である行や列だけを抜き出すことができます。
pandasのSeriesオブジェクトと数値や文字列を比較演算子で比較すると、Seriesの個々の要素と比較した結果を並べたSeriesオブジェクトが得られるので(Seriesオブジェクトはシーケンスとしての性質も持っていることに注意)、これらを利用して
is_valid = df.loc[:,'key_resp.rt'] < 1.0
valid_responses = df.loc[is_valid, 'key_resp.keys']
とすれば、反応時間が1秒未満の試行のkey_resp.keys列の値だけを取り出せます。
1行目を数式として見ると = と < が同じ行に存在していて奇妙に思われるかもしれませんが。 < は比較演算子で、その計算結果を 代入演算子 = で変数 is_valid に代入しているのですからPythonの式として何もおかしくありません。慣れてきたら is_valid に代入せずに
valid_responses = df.loc[df.loc[:,'key_resp.rt']<1.0, 'key_resp.keys']
と1行で書くこともできます。
「反応時間が1秒未満で、なおかつ正答だった試行」のように複数の条件を指定したい場合は少々複雑です。if文で「AかつB」といった条件を指定するときは論理演算子 and を使ったので
is_valid = df.loc[:,'key_resp.rt'] < 1.0 and df.loc[:,'key_resp.corr'] == 1.0
と書きたくなりますが、これを実行すると
ValueError: The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
というエラーで処理が停止してしまいます。Seriesの個々の要素に対して and を適用するのではなく、要素全体をひとまとまりとみて and を適用しようとして「『要素全体』の真偽値なんてわかんないんだけど」と文句を言っているという感じでしょうか。個々の要素に対して論理演算を行うには、 ビット演算子 を使います(表14.2)。ビット演算とは本来、数値を2進数で表し、1を真、0を偽とみなして論理演算をおこなうものですが、Seriesオブジェクトに使用すると要素ごとに論理演算を行った結果を格納したSeriesオブジェクトを返します。
and に対応するビット演算子は & なのですが、 比較演算子よりビット演算子の方が優先順位が高い ため、先に比較演算が行われるように ( ) で囲む必要があります。結論として
is_valid = (df.loc[:,'key_resp.rt'] < 1.0) & (df.loc[:,'key_resp.corr'] == 1.0)
とすれば「反応時間が1.0秒未満である」と「反応が正当である」の両方を満たす行だけを取り出すことが出来ます。3つ以上条件がある場合もビット演算子で連ねていけば対応できます。
引数 |
説明 |
|---|---|
x & y |
要素ごとに論理積(and)を計算します。 |
x | y |
要素ごとに論理和(or)を計算します。 |
x ^ y |
要素ごとに排他的論理和(xor)を計算します。 |
~x |
要素ごとに否定(not)を計算します。 |
ひとつ気を付けておきたいのは、 & 演算子をはじめとするビット演算子は任意のシーケンスに使用できるわけではないという点です。例えば、listを使って
[True, True, False] & [False, True, True]
としても TypeError: unsupported operand type(s) for &: 'list' and 'list' と言われてエラーとなります。pandasのSeriesオブジェクトのほかには、numpyのndarrayオブジェクトがビット演算子に対応しています。
本章の目的であるRやExcelなどへ橋渡しを考えると、ぜひ解説しておきたいのが 図14.1 の例のように欠損値だらけの実験記録ファイルから、分析に必要な部分だけを取り出す方法です。 例えば、練習試行などは除外して本試行の刺激の色(stim_color)、刺激のX座標(stim_xpos)、押されたキー(key_resp.keys)、反応時間(key_resp.rt)、反応の正誤(key_resp.corr)と参加者ID(participant)のみを取り出したいしましょう。必要な列を取り出すのはここまでの解説に従って以下のようにすればいいはずです。
df.loc[:, ['stim_color','stim_xpos','key_resp.keys',
'key_resp.rt','key_resp.corr','participant']]
しかし、これでは教示画面や練習試行など本試行以外で出力された行もすべて含まれてしまうので、本試行のみを取り出したいところです。
key_respは本試行のルーチンに配置されているはずで、そのルーチン以外で記録され行ではkey_respに関連する出力(例えばkey_resp.keys)はすべて欠損値になっています。
ということは、ここまでの話の流れから「欠損していない行のみ True であるSeriesオブジェクト」を得ることができればうまくいくはずですが、このSeriesオブジェクトはどのようにすれば得られるでしょうか。
これはもう知識があるかどうかの問題なので答えを書くと、Seriesオブジェクトの isna() というメソッドを用います。このメソッドは、「欠損している行のみ True であるSeriesオブジェクト」を返します。
このメソッドをkey_resp.keys列(本試行のみ値が出力されている列なら他の列でもよい)に適用して missing という変数に代入しておきます。
missing = df['key_resp.keys'].isna()
この missing の True のところを False に、 False のところを True に入れ替えないといけないわけですが、 表14.2 で紹介した ~ 演算子を用いるとうまくいきます。
したがって
missing = df['key_resp.keys'].isna()
responses = df.loc[~missing, ['stim_color','stim_xpos','key_resp.keys',
'key_resp.rt','key_resp.corr','participant']]
と書けば responses に欠損していない行だけを含むDataFrameオブジェクトが得られます。
- チェックリスト
pandasのDataFrameから列名と行インデックスを指定してデータを抽出することが出来る。
pandasのDataFrameから列インデックスと行インデックスを指定してデータを抽出することが出来る。
pandasのSeriesに比較演算子を適用して条件に合致する要素は
True、しない要素はFalseであるSeriesを得ることが出来る。pandasのDataFrameから、条件に合致する行のデータを抽出することが出来る。
pandasのDataFrameから、欠損していない行のデータを抽出することが出来る。
14.4. pandasのDataFrameをCSVまたはxlsxに書き出す¶
pandasのDataFrameから分析に必要な部分を抜き出すことができたら、ファイルに保存してみましょう。
CSVファイルに出力するには to_csv() 、xlsxファイルに出力するには to_excel() というメソッドを使用します。
分析に使用する環境(RやExcelなど)で扱いやすい形式を選べばよいでしょう。
変数 reponses に保存したいDataFrameが格納されている時、以下のように保存したいファイルへのパスを引数として呼び出すのが基本です。
responses.to_csv('data/responses.csv') # CSV形式で保存
responses.to_excel('data/responses.xlsx') # xlsx形式で保存
to_csv() と to_excel() の引数は共通のものが多いので、まとめて 表14.3 に示します。
index は、出力しておくと分析中にデータを並び替えてしまった時に元の順番を復元する際に便利かも知れません。筆者自身は index=False を指定することが多いです。
na_rep は分析に使用する環境に応じて作業しやすいように指定すればよいでしょう。
to_csv() に特有の引数では、 encoding が 非ASCII文字を含むデータをCSVファイルに出力してExcelで開く場合 に重要です。
というのも、ExcelはUTF-8でエンコードされたCSVファイルを開く際、ファイルの冒頭にBOM(Byte Order Marker)というコードがないと正しく認識されず文字化けしてしまうからです。
BOM付きのUTF-8を出力する場合はencoding='utf-8-sig'を指定してください。
sep はタブ区切りで出力した方が都合がいい場合などに sep='\t' といった具合に指定します。
to_excel() に特有の引数である sheet_name は、xlsxファイルを出力する際にワークシート名を指定するものです。
引数 |
説明 |
|---|---|
|
各列の先頭にヘッダを出力するなら |
|
インデックスを出力するなら |
|
欠損値の代わりに表示する文字列を指定する。デフォルト値は |
|
(to_csvのみ) 文字コードを指定する。省略するとutf-8で出力される。 |
|
(to_csvのみ) 区切り文字を指定する。デフォルト値は |
|
(to_excelのみ) xlsxファイルでのシート名を指定する。デフォルト値は |
- チェックリスト
pandasのDataFrameをCSVファイルに保存することができる。
pandasのDataFrameをCSVファイルに保存してExcelで開くときに文字化けしないようにすることができる。
pandasのDataFrameをxlsxファイルに保存することができる。
14.5. フォルダ内のファイルをまとめて処理する¶
通常、実験は複数の参加者に対して実施しますので、実験記録ファイルも複数保存されます。ファイル数が数個ならともかく十数個にもなると手作業ではやっていられません。 複数のファイルに同じ処理を行うのは人間よりPCの方が圧倒的に得意なので、PCに任せてしまいたいところです。
Pythonで「同一フォルダ内に含まれる、同じ拡張子のファイルを順番に処理」するときに便利なのがglobというモジュールの glob() です。
glob() の使い方を説明するには メタ文字 とか ワイルドカード と呼ばれる文字を解説する必要があるのですが、実例を見た方がわかりやすいので以下の例を考えます。
import pandas as pd
import glob
for file_name in glob.glob('data/*.csv'):
df = pd.read_csv(file_name)
globモジュールを import glob で読み込んでいるので、globモジュールの glob() 関数の呼び出しは glob.glob() となる点に注意してください。
引数の 'data/*.csv' の * がメタ文字で、 * の部分がパスの区切り文字以外の文字であるファイル名が glob() によって探し出されます。
「 * の前後の文字が一致しているファイル名が探し出される」と言った方がわかりやすいでしょうか。
以下の例を考えましょう。
data/ID10200.csv
data/2025-1226-120000.csv
data/2025-1226-120000.xlsx
control/data/ID47244.csv
data/control/ID31124.csv
data/control_ID31124.csv
1.と2.は data/ から始まって .csv で終わっているので、 'data/*.csv' という指定に適合します。メタ文字による指定に適合することを 「マッチする」 と呼ぶことが多いので、以下この表現を用います。
3.は data/ から始まっていますが、最後が .csvで終わっていないので 'data/*.csv' にマッチしません。4.のように data/ の前に別の文字列があってもマッチしません。
5は data/ から始まって .csv で終わっていますが、「 * の部分が パスの区切り文字以外の文字 である」ことがマッチする条件であり、 * に相当する部分に / が含まれているのでやはりマッチしません。6はマッチします。
* 以外にもメタ文字はありますが、とりあえずこれだけ押さえておけば、フォルダ内の実験記録ファイルのみを探し出すには十分でしょう。
glob() は検出したファイル名の文字列を並べたリストを戻り値として返すので、そのままfor文に渡すとファイルを一つずつ処理することができます。
以下のケースを想定して具体的なコードを考えてみましょう。
スクリプトを保存するフォルダにdataというフォルダがあり、その中にある拡張子.csvのファイル(CSVファイル)がすべて分析対象だとする。
CSVファイルのslider.responseという列が空白でない行だけを対象として、participant, stim_image, slider.response, slider.rtという列の値を取り出す。
各CSVファイルから取り出した値をすべてまとめてalldata.csvというファイルに出力する。ただしインデックスはつけないものとする。
import pandas as pd
import glob
columns = ['participant','stim_image','slider.response','slider.rt']
target_column = 'slider.response'
df_all = []
for datafile in glob.glob('data/*.csv'):
df = pd.read_csv(datafile)
df_all.append(df.loc[~df[target_column].isna(), columns])
pd.concat(df_all).to_csv('alldata.csv', index=False)
まずpandasとglobをimportした後、 columns という変数に取り出したい列名のlistを、 target_column という変数に空白でない行を探す列名を代入しておきます。
そして df_all という変数に空のlistを用意しておき、ここへどんどん処理後のDataFrameを追加していきます。
for文とその中身は本章のここまでの解説の集大成なので、わからなければ読み直してください。
for文が終了した後、 df_all には処理されたCSVファイル数と同数のDataFrameオブジェクトが追加されています。これをひとつずつ別のファイルに出力してもいいのですが、今回はalldata.csvというファイルにまとめて出力するので、ひとつのDataFrameファイルにまとめる必要があります。これはpandasの concat() という関数で簡単に実現できます。 concat() の戻り値は結合後のDataFrameオブジェクトなので、この例のように直接 to_csv() を呼び出してファイルを保存することができます(図14.2)。
これまでにBuilderで作成した実験のデータを持っておられたら、 columns と target_column を実験に合わせて書き換えて実行してみてください。取り出されるデータに非ASCII文字が含まれていて、Excelで開いて確認する予定なら to_csv() に encoding='utf-8-sig' を追加するか、 to_excel() でxlsxファイルとして保存してください。

図14.2 「 pd.concat() の戻り値を変数 df に代入する」という処理と、「変数 df に格納されているデータフレームの to_csv() メソッドを呼び出す」という処理を一行にまとめてしまうことができる。本文の例のように pd.concat() の戻り値を後続のコードで使用する必要がない場合に効率的な書き方である。¶
- チェックリスト
globモジュールを使って、dataというフォルダ内にあるCSVファイルに対して順番に処理を実行することができる。
listにおさめられた複数のpandasのDataFrameオブジェクトを結合してひとつのDataFrameオブジェクトにすることができる。
14.6. 簡単な整理をする¶
前節のスクリプトでは、実験記録ファイルの各行がそのままalldata.csvにまとめられます。多くの場合、実験記録ファイルの1行は1つの試行に対応しているので、alldata.csvも1行=1試行の形式でまとめられているということになります。 しかし、その後の分析によっては、参加者ごとに反応時間の平均値や正答率の計算をしてしまった後、1行=1参加者の形式でまとめられていた方が都合がいい場合もあります。
例として、 第3章 のサイモン課題のデータを考えてみましょう。
stim_color, stim_xposというパラメータでそれぞれ刺激の色、刺激のX座標を変化させていて、key_resp.corr(key_respの部分はKeyboardコンポーネントの名前に合わせて読み替えてください)という反応の正誤が記録されていたのでした。さらに「data」というフォルダに分析対象の参加者全員の実験記録ファイル(CSV形式)が保存されていて、それ以外のCSVファイルはdataフォルダに含まれていないとします。
以上を前提として、参加者毎にこれらのパラメータの組み合わせ別の平均反応時間と正答率を計算したものを1行にまとめたCSVファイルを出力するスクリプトの例を以下に示します。
for文を抜けた後、 data_all へ計算結果を追加する際に mean_rt + correct_ratio という式が出てきますが、これは前後のリストを結合する操作を表しています。後半の章で何度か登場しているテクニックですが、まだ読んでおられない場合は「 11.9.1:numpy.ndarray型について 」をご覧ください。
import pandas as pd
import glob
data_all = []
for datafile in glob.glob('data/*.csv'):
df = pd.read_csv(datafile)
mean_rt = []
correct_ratio = []
for color in ['red', 'green']:
for pos in [-0.7, 0.7]:
selected = (df['stim_color']==color) & (df['stim_xpos']==pos)
mean_rt.append(1000 * df.loc[selected, 'key_resp.rt'].mean())
correct_ratio.append(df.loc[selected, 'key_resp.corr'].mean())
data_all.append(mean_rt + correct_ratio) # リスト同士の+演算はリストの結合
col_labels = ['RT_赤左','RT_赤右','RT_緑左','RT_緑右',
'CR_赤左','CR_赤右','CR_緑左','CR_緑右']
df_all = pd.DataFrame(data_all, columns=col_labels)
df_all.to_csv('pd_data_all.csv', index=False) # Excelでも扱うならutf-8-sigを指定
df_all.to_excel('pd_data_all.xlsx', index=False) # Excelでしか使わないならこちらの方がよい
ここまでの解説で紹介していないテクニックが2つ使われています。まず、for文の内側で loc を使って対象となるデータを取り出した後、 mean() というメソッドを適用しています。これは名前の通り、DataFrameの各列やSeriesの平均値を計算するメソッドです。記述統計量を計算するメソッドのうち代表的なものを 表14.4 に紹介しておきます。
反応時間については秒よりミリ秒の方が扱いやすいので、平均値を計算した後に1000倍しています。
key_resp.corr列は正答が1、誤答が0で記録されているため、平均値を計算すると正答率になるというのは 第3章 で解説済みですね。
メソッド, 説明 |
|
|---|---|
|
平均値を計算する。 |
|
標準偏差を計算する。 |
|
中央値を計算する。 |
|
最頻値を計算する。 |
もうひとつは最後に data_all からpandasのデータフレームを作成して df_all という変数へ代入している部分です。
ここではpandasのデータフレームを作成する関数 DataFrame() を使用しています。 DataFrame() は多彩な方法でデータフレームを作成できますが、ここでは2つのパターンを紹介しておきます。
ひとつめは方法で、2次元配列(Excelのシートのように縦横にデータが並んでいる様子を想像するとよい)とみなせるものを引数として渡す方法です(図14.3 の「方法1」)。
上記のコードでfor文を使って変数 data_all にリストを1つずつ追加していっているので、 data_all は 図14.3 の「方法1」のリストと同様のレイアウトになっていることをイメージできれば、上記のコードが「方法1」でデータフレームを作成していることがわかると思います。この方法では、各列の名前は引数 columns に列名を順番に並べたシーケンスを渡して指定します。

図14.3 DataFrame() によるデータフレームの作成。2次元配列状にデータが整理されている場合は方法1、それぞれの列で別のリストにまとめられている場合は方法2が便利。¶
ふたつめの方法は、データをdictオブジェクトにまとめて引数として渡す方法です(図14.3 の「方法2」)。
dictオブジェクトに含まれるキー名が列名となるので、「方法1」のように引数 columns を使って列名を指定する必要はありません。
個々の列のデータが別々にリストにまとめられている場合はこちらの方法が便利です。
データの一部分は方法1のような配列としてまとまっていて、残りは列ごとに別のリストとしてまとめられているというケースでは、まず配列としてまとまっている部分を方法1でデータフレーム化し、残りのデータをひとつずつデータフレームに追加するということもできます(図14.4)。
具体的に言うと、変数 df にデータフレームが代入されていて、このデータフレームにconditionという列が含まれていない時、 df['condition'] = values のように代入すると、conditionという列がデータフレームに追加されて、変数 values の内容がcondition列の値となります。 values に含まれている要素の個数が df の行数を一致しない場合はエラーになりますが、 values が数値や文字列などの単独の値の場合はエラーにならず、すべての行がその値で埋め尽くされます。

図14.4 2次元配列状にまとめられたものと、列ごとにまとめられたものが混在している場合は、まず 図14.3 の方法1でデータフレームを作成して、後から列を追加するのが便利。¶
1列ずつ追加するのではなく複数列のデータをまとめて追加したい場合は、そのデータを DataFrame() でデータフレーム化してから、前節の concat() を使ってひとつのデータフレームにまとめるとよいでしょう(図14.5)。
前節で concat() を使った時はforループを使って個人ごとに作成したDataFrameオブジェクトを縦方向に連結する(つまりすべてのデータフレームが同じ列名を持っていて、同じ列名同士を連結する)のに使いましたが、引数 axis に 1 を指定することで横方向に連結することができます(axis については「 14.7.1:引数 axis に関する補足 」で解説します)。
横方向に連結する際、それぞれの データフレームに同じ名前の列が含まれていてもそのまま連結されてしまう(同じ名前の列が複数存在する状態になる) ので注意してください。列名を使って列を抽出しようとすると、同じ名前の列がすべて含まれるDataFrameオブジェクトが返されます。

図14.5 2次元配列状にまとめられたデータが複数ある場合は、それぞれを DataFrame() でデータフレーム化した後、 concat() 関数に引数 axis=1 をつけて呼び出せば1つにまとめることができる。¶
以上、 第3章 のサイモン課題のデータを題材として、参加者ごとに平均値を計算してからひとつのファイルにまとめて出力するというケースを考えてみました。 本格的な分析はRやExcelなどに引き継いで実施するのであれば、Python上でこのくらいの処理ができれば十分ではないかと思います。
- チェックリスト
pandasのSeriesに対して平均値を計算することができる。
DataFrameオブジェクトに新たな列を追加することができる。
複数のDataFrameオブジェクトを横方向(列数を増やす方向)に結合することができる。
14.7. この章のトピックス¶
14.7.1. 引数 axis に関する補足¶
axis はnumpyやpandasを使用するうえで重要な役割を果たしますが、ちょっと説明がややこしいので本文から分離してトピックにしました。以下のような多重リスト(シーケンス)を考えます。
x = [[[1,2,3,4],[5,6,7,8]],
[[9,10,11,12],[13,14,15,16]],
[[17,18,19,20],[21,22,23,24]]]
このリストは3重になっていて、まず [1,2,3,4] のように連続する4つの数字が並んだリストが2つ、 [[1,2,3,4],[5,6,7,8]] のようにまとめられています。さらに、そのようなリストが3つまとめられているという構造です。このように、それぞれの階層で要素数が揃っていることに着目してください。
このような多重リストから作られたnumpy.ndarrayオブジェクトにおいて、一番外側の階層を0として、その直下の階層を1、さらにその直下の階層を2…と番号づけたものを axis と呼びます。
図14.6 左端は、 x の階層構造がわかりやすいように書き換えたものです。赤、緑、青に着色してあるのはそれぞれ axis=0, axis=1, axis=2 に対応する括弧です。
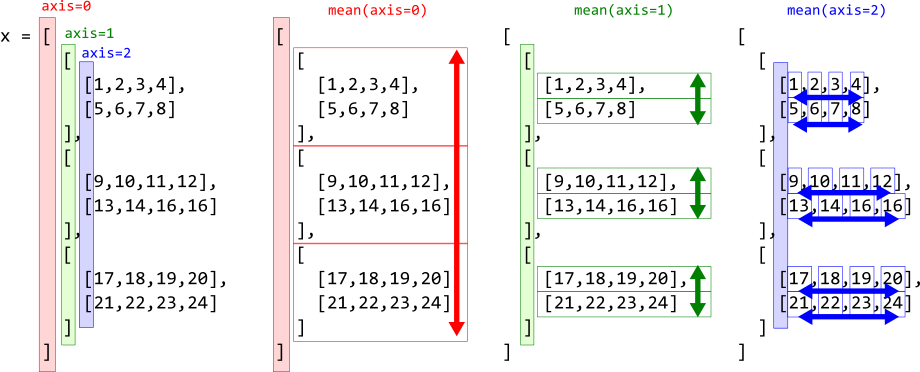
図14.6 左端:3重のリストから作られたndarrayオブジェクトのaxis。 左から2番目から右端:各axisについての mean() の計算。¶
ndarrayオブジェクトのaxisの数(階層数)は ndim 、各axisの要素数は shape で調べることができます。上記の x からndarrayオブジェクトを作成して ndim 、 shape を調べてみます。
import numpy as np
a = np.array(x)
print('ndim:{}, shape:{}'.format(a.ndim, a.shape))
実行すると ndim:3, shape:(3, 2, 4) と表示されます。axisは3つで、第1axis(axis=0)が要素数3、第2axis(axis=1)が要素数2、第3axis(axis=2)が要素数4です。 図14.6 とよく見比べてください。
さて、 表14.4 で紹介した記述統計メソッドは引数 axis を持ちますが、これは計算をどのaxisで行うかを指定するものです。
この「第1axisについて平均する」というのが言葉ではうまく説明できないのですが、例えば平均値を計算する mean() の場合、 図14.6 に示したように、指定されたaxisの要素について計算をおこないます。 axis=0 なら一番外側の [] で囲まれる3つの2次元配列について、 axis=1 なら外側から2番目の [] で囲まれる2つの1次元配列について、 axis=2 なら外側から3番目(つまり一番内側)の [] で囲まれている4つの数値について平均を計算するというわけです。
結果として、指定したaxisがなくなったshapeを持つndarrayオブジェクトが返ってきます。
つまり、shapeが(3,2,4)でaxis=0で平均すると(2,4)のshapeを持つarrayオブジェクトが得られます。同様にaxis=1なら(3,4)、axis=2なら(2,3)のshapeのarrayオブジェクトが得られます。上記の a に対して実際に計算してみましょう。
print('#axis=0で平均\n{}'.format(a.mean(axis=0)))
print('#axis=1で平均\n{}'.format(a.mean(axis=1)))
print('#axis=2で平均\n{}'.format(a.mean(axis=2)))
出力は以下の通りです。 図14.6 と見比べてください。
pandasのDataFrameにも、本文で使用したようにnumpyのndarrayと同様に axis を持つメソッドがあります。働きも同じです。
ただ、DataFrameは基本的にndim=2ですので、 axis=0``は列方向の計算、 ``axis=1 は行方向の計算と覚えておいて問題ないと思います。
本文で出てきたDataFrameを結合する concat() の引数 axis も同様に、 axis=0 なら列方向に結合、 axis=1 なら行方向に結合です。